Here are some very good resources on Molecular Structures - with emphasis on proteins:
The Pdb database contains ALL of the protein structures that were ever solved (or protein-complexes with antibiotics, DNA/RNA, cofactors etc). The
database compiles both NMR-derived and crystallography-derived structures. There are new ones every day, it is a big field in biochemistry (structural
biology). Basically, with the availability of a protein structure one can sometimes predict its functions, its binding site, or its catalytic activity
(etcetc). With today's software, one can then model inhibitor molecules that bind to a section of the protein and inhibit an undesired property
(rational drug design).
Altogether, structures are of immense importance, perhaps knowing or being able to predict all the structures (plus functions etc) of all
proteins/complexes in living cells will be one of the biggest revolutions in science.
Anyway, here you can download thousands upon thousands of structures:
Type in any protein name, i.e. hemoglobin or whatever you can think of. You can view the structure directly on the page, but you can also download the
structural coordinates and view them with free software (see below)
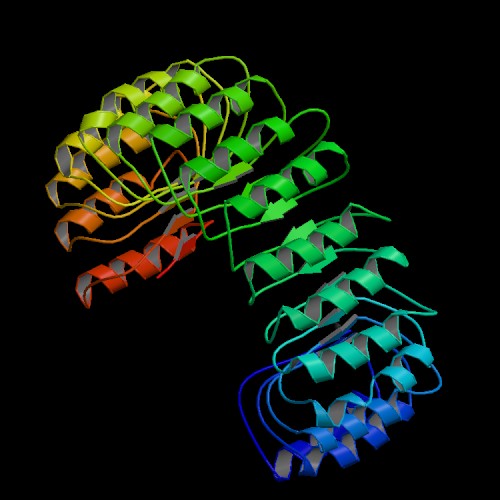
This is one of my favourite structures - the ribonuclease inhibitor (perfect symmetry, and an extremely potent binder of its target molecules,
dissociation constants are in the femto-molar (10^-15 M) range!):
Anyway, to view structures yourself, rotate it in three dimensions in *real time*, to create stereo images (like the Magic Eye book),
or visualise surface charge/polarity, bond lengths etc, check those software packages - they are very easy to use, and fun to play with.
Swiss Pdb viewer - great program. Together with PoVRay (www.povray.org), one can generate beautifully rendered images, with shadows etc. See http://ca.expasy.org/spdbv/
WebLab Viewer Lite - very easy, limited functions, but generates very nice renderings. I would look at that one first if I had never
played with molecular structures. http://www.micro.uoguelph.ca/jwood/amp/Help/WLdown.html
PyMol - perhaps one of the best, albeit new. Extremely powerful, allows you to create beautiful renderings, i.e. semi-transparent
ones with surface charge maps etc. http://pymol.sourceforge.net/
It's the molecular viewer of choice for my school work. It's a great visualization tool. It is very fast, taking full advantage of
accelerated OpenGL. It performs like a dream on my primary Athlon/Geforce2 workstation. Oddly, it is much slower on the far-more-expensive
Itanium2/Quadro2 workstation that I use less often. But on the usual machine, it'll play back 1000 frames of molecular dynamics snapshots, 30
fps, fullscreen, without a hitch. The interface is pretty nice and the scripting abilities are even nicer.
Rasmol is not nearly as nice, but it's also a much smaller download and doesn't need OpenGL. It also has at least one visualization mode
that PyMol doesn't.
It would be nice if PyMol was a molecular builder/editor as well as visualizer, but that's a lot of additional capabilities to add. I found <A
HREF="http://www.uku.fi/~thassine/ghemical/">Ghemical</A> to be a pretty nice molecule-builder when I used it in beta a year ago.
<A HREF="http://ecce.emsl.pnl.gov/">ECCE</A> is the primary molecule-building software I use. It is very powerful, but it's
also somewhat buggy, dependent on Unix/Motif, and not widely available. It also lacks scripting capabilities, which means that I spend a lot of time
performing certain tasks by hand.
<A HREF="http://www.cachesoftware.com/cache/index.shtml">Fujitsu CAChe</A> is a program that I used a bit as an undergraduate.
It's molecular modeling, visualization, and computational chemistry all rolled into one suite of programs. The niftiest use I ever saw: quickly
building a caffeine molecule and then computing its expected UV absorption to save us a walk to the library during a lab.chemoleo - 1-2-2004 at 12:25
Great Stuff Polverone! I was hoping that someone might come up with more molecular building/editiing programs. Shame most are for unix platforms
however.
You see, in crystallography and NMR we mainly use molecular viewing/rendering (with the progs in my prev. post), and for the actual structure building
certain specialist programs are used.
Aside from this - do you know any decent modelling programs (free) with which I could for instance do crude energy minimisations to find the optimal
way a peptide is bound to a protein? Of course I know roughly the binding pocket, but detailed interactions will have to be done by E.M.. This is one
of the problems I will be facing soon ... building a model where the full protein structure is known, and where the orientation of the peptide is
known... but not the detailed interactions Polverone - 2-2-2004 at 16:02
I use Linux or other Unices almost exclusively, so I tend to notice software that's available for these platforms. For Windows users on a budget,
I've heard good things about <A HREF="http://www.hyper.com/products/Lite/lite20.html">Hyperchem Lite</A>. There's
always warez too, since finding illegal free copies of software for Windows is about as hard as stubbing your toe.
I don't know enough about proteins to answer your second question intelligently. I know that it takes us days of QM calculation on a
supercomputer to get the electronic structure of small DNA snippets, or to do a 2 nanosecond molecular dynamics simulation of slightly larger DNA
snippets, and I think proteins are quite a bit more complex. I don't know what sort of shortcuts you'd have to take to get results in a
reasonable amount of time on a single desktop machine. Or do you have a supercomputer or cluster available for these calculations?chemoleo - 2-2-2004 at 16:23
Well clusters are certainly available. However, I dont think it is totally unfeasible for a decent Athlon - in a different lab things took a day or
two to model inhibitor binding to protiens (on an old Silicon Graphics computer which pales to todays PCs!). This was done with molecular simulations
(MSI) which is not particularly good, old, and very expensive (and not a particularly accurate simulation).
Also, if most hydrogen bonds are known in the structure (i.e. found via NOEs/Nuclear Overhauser Effects in NMR), it shouldnt be that hard to model the
peptide onto it.
Anyway, I will look into it and post later on what I find out what is best
[Edited on 3-2-2004 by chemoleo]
Hyperchem impressions and a question
Polverone - 10-8-2004 at 14:13
I'm currently using an evaluation copy of Hyperchem 7.51, since there's another group that I work with that uses it all the time, and it
offers some capabilities that my other software doesn't. I've used it for a couple of days now.
Initial impressions:
--The "native" scripting language is extremely simple but seems to allow comprehensive access to Hyperchem functionality. This is a big
plus, and in fact the only reason I'm considering using this package more regularly. Tcl scripts are also possible, but so far I've been
writing my scripts in Python (scripts to write scripts) and then running the generated native-scripting-language scripts in Hyperchem.
--There's a real grab-bag of tools in Hyperchem: you can do calculations of molecular dynamics, Langevin dynamics (seems to be a computationally
cheap approximation to MD with solvent), "Monte Carlo" (seems to be another specialized application of MD), vibration, transition state, NMR
spectra, orbitals, vibrational and electronic spectra, conformational search, and QSAR properties. What a mouthful! Unfortunately, (since many of
these calculations will be computation-intensive), there seems to be no way to set up Hyperchem to run calculations on a cluster. Ironically, given
that Hypercube Inc.'s first product was a molecular modeling system for highly parallel "transputers," current versions of Hyperchem do
not even take advantage of multiple local processors on a multiprocessor machine.
--I really miss having a spreadsheet-type interface that shows all my molecules and atoms with associated parameters (charges, 3D coordinates, AMBER
atom types, etc.) like I have in ECCE.
--The display modes are pretty ugly. Large molecules are tough to look at because there's no easy way to display just your region of interest.
Why? You have to select things visually or already know what atom/molecule numbers you're interested in (since there is no spreadsheet). Large
molecules are also tough to look at because there is no depth cueing/fog option in the display to give you a sense of Z-distance.
--You have to click on an icon or menu item every time you switch mouse modes: one icon for drawing atoms/bonds, one for selection, one for rotating
out-of-plane, one for rotating in-plane, one for translation, one for Z-translation, one for zoom. There are no keyboard shortcuts or modifiers to
switch modes. This drives me nuts. I really don't know what the developers were thinking.
I am currently trying to find a simple solution to a problem I face in Hyperchem. I am importing PDB files generated from a MD simulation of damaged
DNA. Hyperchem does not recognize the damaged (non-standard) residue, so it loads it as 34 separate molecules, 1 atom per molecule, instead of keeping
all the atoms in the residue grouped together. I need to figure out how to turn this group of atoms into a single molecule (even a
chemically-impossible monstrosity of a molecule will do) so that I can run RMS Fit and Overlay calculations against a similar but undamaged residue
taken from another MD simulation. If we have any Hyperchem gurus here, please speak up.
Re: Hyperchem
JohnWW - 10-8-2004 at 17:36
Can you tell us from where you downloaded the Hyperchem 7.51 trial, please? I presume it is the latest version.
I have Hyperchem 6 and 7 with crack, but I have not used them lately - too busy on other things. I note that they are not on the FTP, so unless you
upload v.7.51 soon I will upload these.
In case anyone wants to know, I downloaded Hyperchem 6 & 7 and cracks for them in November 2002 from the following URLs, which may no longer be
availlable (I have not checked):
Since the only restriction on the trial version is that it stops working after 10 days, it should be trivial to crack. If nothing else, you could
install it on a pristine system image under Virtual PC or VMWare every 10 days. But if it proves useful enough, it will be purchased for me, so I
haven't tried hunting down a crack for it.Hulk - 19-8-2004 at 11:13
If anyone does not want to have linux on their machines but wants to use the software available for linux. Why not try this
You can set it up to run right off of the Cd-rom and you do not need to partition your systems it puts it all back when done.
Hulk
Hyperchem followup
Polverone - 19-8-2004 at 11:59
My evaluation license has expired now. I never did get it to do what I wanted it to do. I was able to import (some) nonstandard residues in a
semi-reasonable fashion by renaming them to standard residue names within the PDB files.
Then I discovered that the RMS Fit and Overlay calculation apparently isn't scriptable. It is accessible from a menu, and the manual says that
every menu item has a corresponding script command, but this one doesn't. I posted a query about it a week ago on the hyper.com message board but
received no response.
While trying to track down other support channels I found a number of complaints about various quirks or bugs in Hyperchem. Niche software like this
is often buggy, even more so than ordinary desktop sofware. It's disappointing that the first non-trivial task I tried to accomplish with it
proved impossible or (at best) very awkward.
My evaluation-period impression of Hyperchem was that it was no more powerful or friendly than the zero-cost academic/government software already out
there. The little advantage that it has in making so much functionality available in a point-and-click interface is offset by the difficulty in
automating or scripting tasks, and automation is a must for serious work. The only catch is that many of the zero-cost packages are only available to
academic institutions, not Joe Compuchem who wants to use the software at home.chemoleo - 19-8-2004 at 14:28
Quote:
The only catch is that many of the zero-cost packages are only available to academic institutions
What do you mean by this? Which ones are publicly not accessible and yet available for free to academic institutions?
I always thought that programs that are free for academic institutions are NOT free for companies/corporations, yet free for the occasional Joe
Compuchem?!?Polverone - 19-8-2004 at 17:25
The computational chemistry package that I use most often is NWChem.
From the <A HREF="http://www.emsl.pnl.gov/docs/nwchem/nwchem.html">download page</A>:
"Please Note: In order to obtain NWChem, you must be a permanent faculty or staff member of the facility or institution you are associated with.
We can NOT accept User Agreements from students or post docs."
The molecular modeling software Ecce, designed for use in conjunction with NWChem, also <A
HREF="http://ecce.emsl.pnl.gov/using/download.shtml">requires a signed user agreement</A>, but doesn't have the same bold
disclaimer about persons unqualified to obtain the software. I don't know if Ecce redistribution is more relaxed, or if requests from Joe
Compuchem would be weeded out at the approval stage (all requests are human-approved).
The <A HREF="http://www.msg.ameslab.gov/GAMESS/License_Agreement.html">GAMESS License Agreement</A> implies that everyone who
obtains it will belong to a research institution or corporation, though I may be reading too much into that.
The instructions for <A HREF="http://www.scripps.edu/pub/olson-web/doc/autodock/obtaining.html">obtaining Autodock</A> say that
"You and an institutional representative, such as your Head of Department, are required to sign and return a Software Distribution
Agreement." This too sounds like an individual wanting the software won't get very far.
It <A HREF="http://gulp.curtin.edu.au/manuals/index.cfm">appears</A> that GULP may be another member of the
"academics-only" club.
(...and at this point I gave up looking for more examples)
It appears that things aren't as grim as I thought. I remember that a couple of years back I started looking for zero-cost computational
chemistry tools, and it seemed that every package I stumbled across had some onerous licensing requirements. I must have just been looking at the most
restrictive software by chance, or maybe I didn't want to provide a signed license agreement just to try packages.
There are also a number of software packages that have token license fees by institutional standards, but substantial fees by individual standards (a
few hundred dollars per site at most); this group includes Amber and all the Quantum Chemistry Program Exchange software.
Then there's software that started out as freely distributed academic tools and was later commercialized (Gaussian and Mopac, at least). This
software is priced beyond many small academic groups, much less curious tinkerers.
Another unfortunate thing is that it seems it is the most mature, powerful, well-documented software that is likely to be priced or licensed in a way
that makes it difficult for hobbyists or tinkerers to use it. It seems that there are a number of completely free (no signed license agreement or
money needed to download) computational chemistry packages, but I don't know how many have convenient front-ends for graphically building systems
and examining computation output. That is a valuable part of the Ecce/NWChem combination, even though I spend more time with the text-based
programming interface than the graphical builder. People who want to play with computational chemistry will generally have to know a considerable
amount about the "computational" side of things, even down to internal implementation details, before they can do any chemistry. I think
many more chemists and chem-hobbyists could probably make use of computational chemistry if they didn't have to have a programming/math/pchem
background to use the available tools.thefips - 28-8-2004 at 16:49
It looks like it has some pretty good features, especially for Windows freeware! The implementation may or may not live up to the promise of its
feature list, but that's why it needs to be tried.